2. Big data
2.1. Qué es big data
Es un término de actualidad y, por ello, podemos encontrar infinidad de definiciones del mismo que varían según el enfoque de diversos autores. A continuación exponemos las más notorias:
La primera presentación de este término se le atribuye al MGI (McKinsey Global Institute, 2011), que lo definió del siguiente modo: big data (datos masivos o datos a gran escala) se refiere a los conjuntos de datos cuyo tamaño está más allá de las capacidades de las herramientas del software de bases de datos típicas para capturar, almacenar, gestionar y analizar.
Por otro lado, una aproximación más completa al big data es la facilitada por Gartner (2012): «Son activos de información caracterizados por su alto volumen, velocidad y variedad, que demandan soluciones innovadoras y eficientes de procesado para la mejora del conocimiento y toma de decisiones en las organizaciones».
Marr (2016), por su parte, establece que el big data es un término que hace referencia al hecho de que actualmente podemos recoger y analizar los datos en modos que eran impensables hace unos años. Hay dos aspectos que están impulsando este movimiento: el hecho de tener más datos sobre cualquier cosa y nuestra capacidad mejorada para almacenar y analizar cualquier tipo de dato.
González (2017) determina que big data no es solo tecnología, sino que es una combinación de negocio y analítica de datos. Además, big data debe dar solución a problemas de:
- Gran volumen de información que hay que manejar → Volumen.
- Distintos tipos de información → Variedad.
- Procesamiento en tiempo real → Velocidad.
Debe ser capaz de adecuar de forma dinámica y escalable la infraestructura necesaria en cada momento, flexibilizando costes y teniendo la capacidad de poder analizar virtualmente cualquier tipo de negocio.
En último lugar, según Ureta (2018), del grupo Arena Consulting, el big data es un conjunto de nuevas tecnologías capaces de obtener valor de datos (convertirlos en información y conocimiento) que, por sus características, situación, volumen, variedad o velocidad antes no se aprovechaban.
2.2. Las cinco uves (5 V) del big data
En la actualidad, alrededor del 65 % de los proyectos que se inician basados en big data en España fracasan (Ureta, 2018). Esta coyuntura se da porque las empresas no están preparadas para afrontar su implementación, no disponen de personal formado y especializado y existe un gran desconocimiento de esta materia. Esta ignorancia operacional viene dada por la complejidad de los datos y por su principal desafío: las 5 V.
La gran generación de Volúmenes de datos que se producen a diario, sumado a la Velocidad con la que lo hacen, y la extensa Variedad de procedencia, hacen que el procesamiento y análisis se convierta en un proceso de selección complejo. Por esta razón, se añaden al proceso dos nuevas uves, Veracidad y Valor, imprescindibles a la hora tomar decisiones y maximizar la rentabilidad.
Podemos afirmar que el big data es un concepto que se equipara con la distribución en procesamiento, consistente en el almacenamiento y la analítica avanzada.
Cuadro 2. Las 5 V del big data
Característica | Explicación |
|---|---|
Volumen |
Alusión al gran tamaño de generación de datos diarios, ya sean generados por parte empresas o usuarios. |
Velocidad |
Hace referencia a la rapidez en la que fluyen los datos, así como al tiempo de procesamiento a tiempo real. |
Variedad |
Los datos provienen de diferentes fuentes, ya sean estructurados, no estructurados o semiestructurados. Esta variedad es la que afecta directamente a la complejidad de almacenaje y análisis de los mismos. |
Veracidad |
Dado el gran volumen de datos que se genera, es necesario analizarlos para garantizar así la autenticidad y fiabilidad para la posterior toma de decisiones. |
Valor |
Este contexto menciona la necesidad de seleccionar aquellos datos que sean útiles para poder rentabilizarlos y generar ventajas competitivas. |
Fuente: Elaboración propia basada en el modelo de las 5 V de Marr (2015). |
|
2.3. Tipos y fuentes de datos
Atendiendo a la clasificación de datos de Joyanes (2013), se distinguen tres categorías de datos según su procedencia:
- Datos estructurados. Aquellos que se presentan en un formato o esquema bien definido y que poseen campos fijos. Son hojas de cálculo, archivos, bases de datos tradicionales provenientes de CRM, ERP, etc., que han sido recolectados por profesionales del marketing en algún momento.
- Datos semiestructurados. No tienen formato definido, pero sí contienen etiquetas u otros marcadores con el fin de clasificar los elementos de los mismos. En esta categoría encontramos textos con etiquetas XML y HTML.
- Datos no estructurados. Los más numerosos. Son datos de tipo indefinido, almacenados principalmente como documentos u objetos sin estructura fija ni bajo ningún patrón concreto. Pueden ser generados por máquinas y personas. Son archivos de audio, vídeo, fotografía y formatos de texto libre como emails, SMS, artículos, WhatsApp, etc.
Por otro lado, los datos, independientemente de su estructura, provienen de diversas fuentes. Estas pueden clasificarse en varias categorías. En este estudio referenciamos la clasificación aportada por Soares (2012), recogida en el siguiente cuadro:
Cuadro 3. Tipos de datos según su origen
Fuentes | Descripción | Tipo de dato |
|---|---|---|
Web and social |
Engloba todo contenido proveniente de las páginas web e información obtenida de redes sociales. |
|
Machine-to- |
Machine (M2M)Hace referencia a la comunicación entre máquinas. Son aquellas tecnologías que habilitan la conectividad entre dispositivos a través de sensores. |
|
Big transaction data |
Datos de transacciones provenientes de centralitas de telefonía, atención al cliente, banca, etc. |
|
Biometrics |
Esta información tiene gran relevancia en sectores como la seguridad, gobiernos, servicios de inteligencia, etc. |
|
Human generated |
Datos generados por las personas en su día a día. |
|
Fuente: Elaboración propia a partir de Soares (2012). |
||
2.4. Analítica de datos
Es la capacidad de extraer información relevante con base en un análisis de datos a partir de técnicas estadísticas, nuevas tecnologías o inteligencia artificial, con objeto de resolver problemas empresariales y ayudar en la toma de decisiones estratégicas.
Figura 3. Tipos de analítica de datos
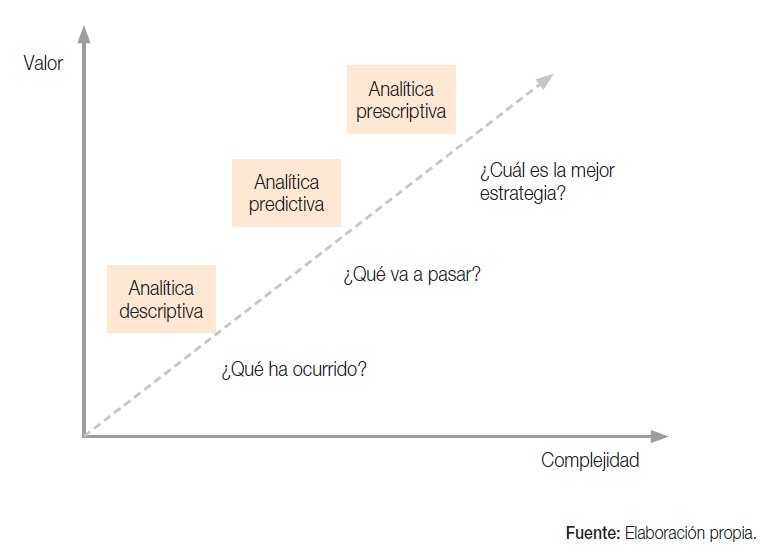
2.4.1. Analítica descriptiva
La analítica descriptiva es el tipo de analítica más simple, ya que se utiliza una serie de técnicas sencillas como medias, desviaciones típicas, gráficos, etc. Es una etapa preliminar de procesamiento de datos que trata de contestar a preguntas sobre hechos que ya se han producido.
Esta analítica permite a las empresas conocer qué ha sucedido en el pasado para conocer la situación actual en la que se encuentran, de manera que se identifican tendencias, patrones y excepciones.
Dentro de este apartado cabe mencionar el término business intelligence, dado que se puede acotar como un tipo de analítica de datos descriptivo. Business intelligence es, por tanto, «la habilidad de aprender las relaciones de hechos presentados de forma que guíen las acciones hacia una meta deseada» (Schmarzo, 2014).
De manera general, la información que se extrae de business intelligence se organiza siguiendo dos modelos (González, 2017):
- Data warehouse. Almacén de datos estructurados que proporciona servicio a toda la empresa y permite la integración de la información de los distintos departamentos o áreas de negocio.
- Data mart. Repositorio estructurado de datos que proporciona servicio generalmente a una sola área del negocio; por ejemplo, al área comercial.
2.4.2. Analítica predictiva
La analítica predictiva pretende predecir resultados basándose en tendencias, patrones y anomalías dentro del histórico de datos. Su núcleo se basa en la relación de variables explicativas y sucesos pasados, que permiten explotarlos para predecir un resultado futuro.
Este tipo de analítica está ligada al data mining y al data science. El data mining o minería de datos es el proceso automatizado para el descubrimiento de información relevante en cantidades de datos masivas. Por su parte, el data science es la extracción de conocimiento a partir de datos.
Otra de las herramientas que utilizan la analítica predictiva es el machine learning, que se basa en algoritmos que aprenden a partir de datos históricos y en algunos casos permiten crear modelos de propensión.
Por su parte, los modelos de propensión estiman la probabilidad de que suceda algo en el futuro a través del análisis de datos recogidos en el tiempo.
2.4.3. Analítica prescriptiva
La analítica prescriptiva trata de determinar las acciones que deben llevarse a cabo ante una situación concreta basándose en modelos predictivos. Este sistema analítico aporta recomendaciones óptimas sobre dichas acciones.
Puede decirse que es una combinación entre la analítica predictiva y los algoritmos de optimización. No solo se predice lo que puede suceder, sino también las causas, y se añaden recomendaciones respecto a las acciones que se aprovecharán de esas mismas predicciones.
Algunas de las metodologías más utilizadas dentro de estas categorías son: muestreo, calidad de los datos, preparación de los datos, modelización y evaluación.
2.5. Roles en big data
Con el auge del big data en los últimos años, ha acontecido el nacimiento de nuevos roles y profesiones. El futuro estará en aquellas personas capaces de analizar el gran volumen de datos y visualizar en ellos el valor añadido que estos pueden aportar a las organizaciones. Los nuevos perfiles que han surgido en torno al ecosistema del dato son:
- Chief data officer (CDO). Es el profesional con mayor rango dentro de la gestión de datos. Asume responsabilidad sobre el gobierno del dato, su calidad, normativa y regulación, y desarrolla estrategias para convertir la información en ingresos o activos.
- Architect. Es el encargado de seleccionar los módulos y las herramientas apropiados. Cuenta con conocimiento de administración de sistemas y desarrollo de software.
- Data scientist. Lleva a cabo el análisis y limpieza de datos, así como el prototipado de algoritmos. Además, domina las herramientas de machine learning.
- Data engineer. Se encarga de proporcionar la infraestructura de datos para su posterior análisis con la construcción de diferentes elementos como bases de datos.
- DevOps. Lleva a cabo la tarea de unificación del desarrollo software y la operación de software.